
Posted:05/15/2015 6:44AM
Data Padding and Alignment in Visual Studios C++
Mike Mclain discusses Data Padding and Alignment in Visual Studios C++
Posted:05/15/2015 6:44AM
Mike Mclain discusses Data Padding and Alignment in Visual Studios C++
Before I transgress the natural order of programmers civility, and delve into the programming language C++ (or archaic remnant of some programming heyday thereof), allow me to put the constructs behind this article into proper context beginning with a little personal background.
To begin, my programming story dates back to my early childhood (to the time when I was around five or six years old) in which I was introduced (by my dad and granddad) to the area (of programming) through the programming language FoxPro (which is a DBMS and scripting language that has subsequently been replaced by Access, SQL, MySQL, SQLite, et cetera).
Now, while I will not bore you with the agonizing details of five-year-old me learning how to program (not that I can really remember such details anyways), I will; however, elaborate on the sequence of events that led me to the clutches of despair that is C++. As time and my programming skills progressed, I eventually learned how to program in Visual Basic 6 and somehow got involved with reverse engineering/hexing (the game NetStorm: Islands At War) by my freshman year of high school.
Likewise, because reverse engineering/hexing (in my particular case) generally required disassembling an executable (I believe I utilized WIN DASM for this task), analyzing the extracted assembly instructions, and then (using a hex editor, like the one provided by Visual Studios or Hex Workshop) modifying an executable's assembly (most primitively accomplished by replacing assembly operations with the no operation or nop 0x90 command) to achieve some desired objective (like getting infinite money, or fixing a deliberately introduced game breaking bug like ZAssert).
Conversely, while I will not venture into the contemporary legalities of such exploits nowadays (as times were much simpler back then and arguably a happier shade of gray than they are today); however, I will summarize my earlier escapades (into reverse engineering/hexing) by stating that I learned a lot from my adventurous exploration of disassembled assembly and that I owe a lot to the core game NetStorm developers: Zack Booth Simpson, Ken Demarest, Tony Bratton, and Jim Green for their (inadvertently) wonderful educational platform, that is NetStorm: Islands At War (noting the obvious, the game was also great fun as well!).
Similarly, by the time I reached my senior year of high school, I was able to enroll in AP computer science (taught by the wonderful Ruth Hartsook, which at the time was focused solely on C++ but has since migrated towards teaching Java Programming) and using my knowledge of assembly for leverage (albeit my knowledge was insanely green at the time when compared to hardware engineering gurus like John Miles) I was successfully initiated into the C++ occult (and also started a short-lived karaoke career by performing a duet with Ruth to the "Let It Be" cover Write in C by Jay Piecora) and successfully obtained AP college credit for "CSCI 2050 Topics In Computer Science" that I promptly never could apply to my degrees during my 10 year tenure in the UNCC Electrical Engineering program.
Now, while most greenhorn programming stories normally take the form "I was an intern at ..., and I wrote ... for ... and I got picked on a lot by ... for taking down ... by ..., et cetera", fate somehow bestowed upon me (around my sophomore year of college) an opportunity to work with the Bismarck Entertainment programming team (a group of individuals who approached and successfully convinced Activision to allow them to create an expansion for the game NetStorm: Islands At War), which ultimately led to me becoming involved with the creation of an offshoot project (dubbed Ticonderoga Entertainment) that produced an unofficial patch (as opposed to an expansion) for the game.
Likewise, my adventures working with Netstorm is best surmised as being a "baptism by fire" into C++ game programming (as the methodologies I encountered are definitively not taught in school) and any green programming bliss my youthful self possessed was promptly charred to ash, liquefied, cast, and forged by Zack's, Ken's, Tony's, and Jim's righteous gauntlet. Conversely, while such tales sound overly dramatic; however, I believe the reflective thoughts of Zack, Ken, and Jim (written during the development of their game) in which they state (and I quote):
"We hereby proclaim that we will never ever ever write anything like this again"
best summarizes and validates my tale.
Nevertheless, while such stories might seem fundamentally designed to permit the shameless introduction of personal nostalgia (although it was an enjoyable ride down memory lane), the subject of data padding and alignment did happen to arise during my recent exploration into creating a 010 Editor binary file template for the Netstorm saved game file format (or .fort file), thus making the previous ramblings very pertinent to this particular discussion.
Likewise, while the gritty details behind creating a 010 Editor binary template will not be discussed within this particular article; however, after encountering a number of C++ data padding/alignment issues (and consequently resolving them), I figured it might be prudent to share some of my observations and experiences on the subject for future reference.
Conversely, while I will not go into excessive detail on every padding/alignment peculiarity (since better sources of information, like Eric Raymond's The Lost Art of C Structure Packing, are readily available and, i would argue, should be mandatory reading for all C++ Programmers); Nevertheless, it is the intent of this article to serve as a cautionary tale to developers seeking a cross-platform/cross-programming/cross-hardware/cross-memory-optimized solution, and hopefully aid someone in achieving such objectives through my recollections.
To begin, (especially within academia) it is frequently postulated that C++ primitive types (like char, short, int, float, et cetera) generally have some finite size (or compiler defined memory allocation) associated with them and although such sizes can be somewhat flexible (an innate problem in itself, since one compiler might define an int to be a short while another might, in a 64-bit architecture, define an int to be a long long); however, the common beginners assumption (per 80x86 architecture in the Visual Studio C++ IDE), which can be obtained by running the following code:
// input is turned into a string literal via #
#define STR(s) #s
// input is printed to console via C printf
// could be replaced by cout << if so desired!
#define PRINT_PRIMITIVE(s) printf("Size of %-20s is %02d Bytes\n",STR(s),sizeof(s));
// a A simplistic function to print each primitive datatype
void Print_Primitive_Sizes()
{
printf("Basic Types\n");
PRINT_PRIMITIVE(bool);
PRINT_PRIMITIVE(char);
PRINT_PRIMITIVE(short);
PRINT_PRIMITIVE(int);
PRINT_PRIMITIVE(long);
PRINT_PRIMITIVE(long long);
PRINT_PRIMITIVE(float);
PRINT_PRIMITIVE(double);
PRINT_PRIMITIVE(long double);
printf("\n\nSigned Types\n");
PRINT_PRIMITIVE(signed bool);
PRINT_PRIMITIVE(signed char);
PRINT_PRIMITIVE(signed short);
PRINT_PRIMITIVE(signed int);
PRINT_PRIMITIVE(signed long);
PRINT_PRIMITIVE(signed long long);
PRINT_PRIMITIVE(signed float);
PRINT_PRIMITIVE(signed double);
PRINT_PRIMITIVE(signed long double);
printf("\n\nUnsigned Types\n");
PRINT_PRIMITIVE(unsigned bool);
PRINT_PRIMITIVE(unsigned char);
PRINT_PRIMITIVE(unsigned short);
PRINT_PRIMITIVE(unsigned int);
PRINT_PRIMITIVE(unsigned long);
PRINT_PRIMITIVE(unsigned long long);
PRINT_PRIMITIVE(unsigned float);
PRINT_PRIMITIVE(unsigned double);
PRINT_PRIMITIVE(unsigned long double);
printf("\n\Pointers\n");
PRINT_PRIMITIVE(unsigned bool *);
PRINT_PRIMITIVE(unsigned char *);
PRINT_PRIMITIVE(unsigned short *);
PRINT_PRIMITIVE(unsigned int *);
PRINT_PRIMITIVE(unsigned long *);
PRINT_PRIMITIVE(unsigned long long *);
PRINT_PRIMITIVE(unsigned float *);
PRINT_PRIMITIVE(unsigned double *);
PRINT_PRIMITIVE(unsigned long double *);
PRINT_PRIMITIVE(unsigned void *);
}generally manifest itself as:
| Type | Base | Signed | Unsigned | Pointer |
|---|---|---|---|---|
| bool | 1 | 4 | 4 | 4 |
| char | 1 | 1 | 1 | 4 |
| short | 2 | 2 | 2 | 4 |
| int | 4 | 4 | 4 | 4 |
| long | 4 | 4 | 4 | 4 |
| long long | 8 | 8 | 8 | 4 |
| float | 4 | 4 | 4 | 4 |
| double | 4 | 4 | 4 | 4 |
| long double | 8 | 8 | 8 | 4 |
| void | N/A | N/A | N/A | 4 |
Likewise, while there are a number of obvious compiler quirks (like signing or un-signing a boolean value results in an automatic integer casting, but who would do that... really?) and such discrepancies would clearly need to be addressed in a cross-platform/cross-programming/cross-hardware/cross-memory-optimized solution; however, such discrepancies are (generally) readily identifiable relative to the more obscure issue of structure padding/alignment.
Conversely, with the byte sizes of primitive types known (at least assumed for this particular exercise), consider the following C++ structure:
struct Chicken
{
short x;
int y;
};Now, by simplistic academic perception (albeit I am hopeful that such assumptions would be corrected in higher level programming classes, then again this might be an egregious assumption on my part), it is commonly presumed (at least by beginners and some intermediaries) that a structures byte size is simply the sum of its parts (in this example it might be presumed that sizeof(Chicken) = sizeof(short) + sizeof(int) or $2 + 4 = 6$); however, execution of the following code (noting that if the pre-compiler directives are too confusing, simply replace with the more intuitive cout<<sizeof()<<endl):
#define PRINT_TYPE(s) printf("Size of %-20s is %02d Bytes\n",STR(s),sizeof(s));
struct Chicken
{
short x;
int y;
};
PRINT_TYPE(Chicken);yields the following output:
Size of Chicken is 08 Bytes
, in which the Chicken has mysteriously acquired two additional bytes of memory when compared to the (commonly presumed) sum of parts assumption.
Likewise, setting the explanation of synergy (or the whole is greater than the simple sum of its parts) aside, some preliminary research on the subject (see also Eric Raymond's The Lost Art of C Structure Packing for a more in-depth explanation) reveals that compilers generally allocate structural data in a procedural manner that tends to maximize CPU cycle efficiency (often times at the expense of memory) for a given CPU architecture.
Conversely, since a 32 bit (or 4 byte) 80x86 architecture was selected (via creation of a 32 bit application within Microsoft Visual Studios C++ ), it makes sense (at least based off of the previous notion of architectural maximization) that the compiler would pad/align the Chicken structure into a (4 Byte) memory configuration that conforms to local (32 bit) CPU register allocation rules (rather than forcing the processor to perform additional operations to resolve nonconforming memory alignments).
Additionally, the overtly curious (regarding local CPU memory alignment rules) might be interested in running the C++ _alignof() macro (warning this macro's name seems to change across compiler distributions), like so:
#define PRINT_ALIGNMENT(s) printf("alignment of %-20s is offset by %02d Bytes\n",STR(s),_alignof(s));
void Print_Alignment_Sizes()
{
printf("Basic Types\n");
PRINT_ALIGNMENT(bool);
PRINT_ALIGNMENT(char);
PRINT_ALIGNMENT(short);
PRINT_ALIGNMENT(int);
PRINT_ALIGNMENT(long);
PRINT_ALIGNMENT(long long);
PRINT_ALIGNMENT(float);
PRINT_ALIGNMENT(double);
PRINT_ALIGNMENT(long double);
printf("\n\nSigned Types\n");
PRINT_ALIGNMENT(signed char);
PRINT_ALIGNMENT(signed short);
PRINT_ALIGNMENT(signed int);
PRINT_ALIGNMENT(signed long);
PRINT_ALIGNMENT(signed long long);
printf("\n\nUnsigned Types\n");
PRINT_ALIGNMENT(unsigned char);
PRINT_ALIGNMENT(unsigned short);
PRINT_ALIGNMENT(unsigned int);
PRINT_ALIGNMENT(unsigned long);
PRINT_ALIGNMENT(unsigned long long);
printf("\n\Pointers\n");
PRINT_ALIGNMENT(unsigned char *);
PRINT_ALIGNMENT(unsigned short *);
PRINT_ALIGNMENT(unsigned int *);
PRINT_ALIGNMENT(unsigned long *);
PRINT_ALIGNMENT(unsigned long long *);
}, in order to obtain local memory alignment rules for the platform (as demonstrated by:
| Type | Base | Signed | Unsigned | Pointer |
|---|---|---|---|---|
| bool | 1 | N/A | N/A | 4 |
| char | 1 | 1 | 1 | 4 |
| short | 2 | 2 | 2 | 4 |
| int | 4 | 4 | 4 | 4 |
| long | 4 | 4 | 4 | 4 |
| long long | 8 | 8 | 8 | 4 |
| float | 4 | N/A | N/A | 4 |
| double | 4 | N/A | N/A | 4 |
| long double | 8 | N/A | N/A | 4 |
| void | N/A | N/A | N/A | 4 |
) for a local programming platform or if more structure specific information is required, the C++ offsetof() macro can be utilized (like so:
cout<<offsetof(struct Chicken,y)<<endl;
) in order to derive (noting that some math will be required) the amount of padding present within the structure at a given type location.
Nevertheless, while I am aware that some hardware architectures, especially older Sun Microsystems SPARC processors (noting that I once had the dubious honor of working with such, physically heavy, behemoths while creating a computational Beowulf cluster), are rather temperamental (as in your code will cause a segmentation fault) when it comes to conforming to structured memory alignment rules. However, because traditional nomenclature (which consist mostly of veteran "war stories") most adamantly recommends that such alignment rules are maintained in order to ensure CPU efficiency (noting that these stories are also frequently applied to modern CPU architectures), I decided to (albeit briefly and far from being remotely definitive) empirically investigate such attributes (at least within the Visual Studio's C++ IDE) for something a touch more quantitative (than veteran "war stories").
Likewise, the first attribute I examined (during the exploration of this particular tangent) was the creation of assembly code by the Visual Studios C++ compiler in order to determine if forcible data structure alignments (via the #pragma pack pre-compiler command) played any role in the amount of assembly generated by the compiler (with the assumption that the compiler might be smart enough to identify any boundary problems prior to performing any computational operations).
Conversely, upon utilizing the Chicken structure (which, while admittedly might be a poor choice for this particular analysis, is a common enough structure within most C++ applications to merit some consideration) to create the following code:
struct Chicken
{
short x;
int y;
};
Chicken Hen;
Hen.x =0;
Hen.y =9;which, in turn, will result in the creation of the following assembly code (via the compiler):
// Hen.x =0; xor eax,eax mov word ptr [Hen],ax // Hen.y =9; mov dword ptr [ebp-8],9
.
Similarly, upon applying the #pragma pack pre-compiler command to the Chicken structure, like so:
#pragma pack(push)
#pragma pack(1)
struct Chicken
{
short x;
int y;
};
#pragma pack(pop)
Chicken Hen;
Hen.x =0;
Hen.y =9;the following compiled assembly instructions are created (via the compiler):
// Hen.x =0; xor eax,eax mov word ptr [Hen],ax // Hen.y =9; mov dword ptr [ebp-0Ah],9
.
Likewise, examination of the generated assembly code (of the aligned versus unaligned cases) reveals the same number of assembly instructions (noting that the number of instructions utilized does not necessarily equal the number of atomic CPU operations required to perform the task) with the only distinguishable difference (between the two) being the memory location loaded into the access register (ebp-8 vs. ebp-0Ah ).
Conversely, unsatisfied with this particular observation (noting that I was hoping for something a touch more definitive), I tried a number of different variations of this experiment for an assortment of different C++ operators ( like ++, --, <<, >>, et cetera) and even modified the Chicken structure and #pragma pack configuration to little avail.
Similarly, after toying around with a various assortment of permutations derived from this particular concept, it can only be loosely concluded that the compiler either is utilizing a computational technique that is alignment independent (which is unlikely) or is "passing the buck" for this particular attribute elsewhere (either to the operating system or CPU directly).
Likewise, because such preliminary examinations were rather inconclusive, I decided to create a number of timed experiments (with the objective of measuring CPU clock cycles) in order to obtain more insight into the subject. Now, although such experiments are truly "back of the envelope" (rather than controlled and precise) by design; however, based upon the following results obtained:




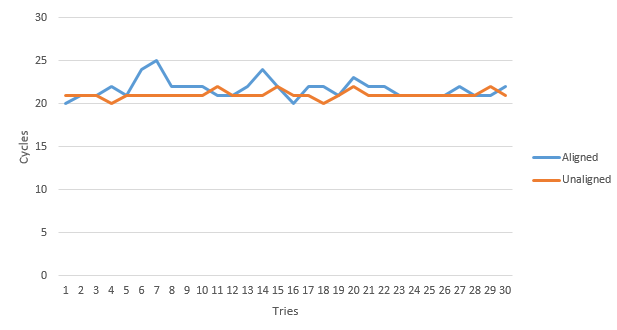
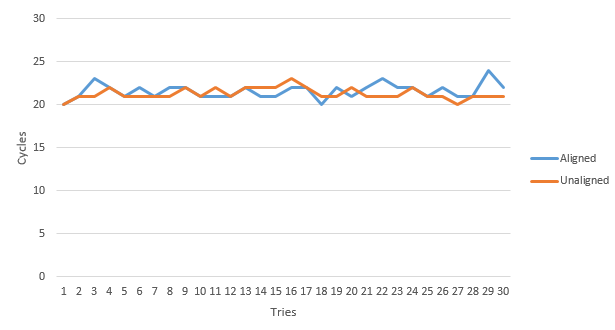

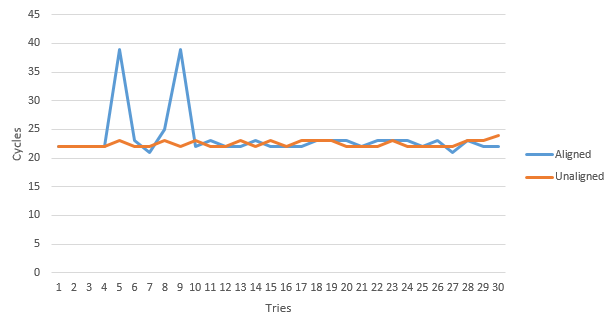

, with the assumption that a defined operation was performed on each Chicken member 10,000,000 times over 30 tries (in order to obtain an average value to account for OS related latency), the following table of averages :
| Operation | Aligned | Unaligned |
|---|---|---|
| Assignment | 24.23 | 25.87 |
| Access | 20.70 | 20.03 |
| Add | 22.47 | 22.27 |
| Subtract | 22 | 22.30 |
| Left Shift | 21.73 | 21.07 |
| Right Shift | 21.60 | 21.30 |
| And | 23.03 | 22.80 |
| Or | 23.03 | 22.80 |
| XOr | 22.67 | 23.07 |
was calculated.
Conversely, upon analyzing the data collected, it seems (at least given this particular data structure) that the unaligned (or #pragma pack) structure utilized (on average) a similar number of CPU cycles as the aligned structure, which is kind of surprising given the overall veracity and taboo this particular issue invokes from the peanut gallery (as I was expecting something on the order of a times 2 increase).
Likewise, additional research on the subject also reveals even more surprising results (relative to the traditional memory alignment arguments); however, such attributes are well beyond my intended scope of discussion (for this particular article) and (despite such counter observations) I believe it is oftentimes best to heed the wisdom of more senior developers (especially when it comes to cross-platform/cross-programming/cross-hardware/cross-memory-optimized programming) where applicable.
Nevertheless, while there are definitively performance related attributes that are associated with memory alignments that often times must be considered (and likely more rigorous sources of information available on this particular subject); however, memory conservation verses computational performance is not the only attribute that must be considered when it comes to cross-platform/cross-programming/cross-hardware/cross-memory-optimized design and such notions are the core rationale behind me creating this particular article.
To elaborate on this attribute further, consider what happens when the previously discussed Chicken object is written to a file (after some preliminary initialization), like so:
#include <iostream>
#include <fstream>
using namespace std;
struct Chicken
{
short x;
int y;
};
int main()
{
Chicken Hen;
Hen.x =1;
Hen.y =9;
ofstream f("output.bin", ios::binary);
f.write((char*) &Hen, sizeof(Hen));
f.close();
}
.
Likewise, upon opening the outputted binary file output.bin (in this particular case using the 010 binary Editor and applying a colorize template), like so:

, it can clearly be seen that an eight byte structure was written to the binary file (as opposed to the desired six byte structure), in which the structure's short (in blue) and the structure's int (in red) are clearly defined (as opposed to the structure's short alignment padding (in green) that appears to be the contents of uninitialized memory).
Now, because a structures memory alignment is highly dependent upon the CPU architecture selected during the compiling process (and a cross-platform/cross-programming/cross-hardware design would likely utilize multiple compilers for each distribution), it becomes apparent that attempting to load a saved memory object back into memory across a diverse number of platforms/hardware devices (for example, attempting to load a saved memory object created by a 32-bit application with a 64-bit version of the same application) can be a potentially volatile exercise if extreme care is not taken during the development of the communication medium (in this particular case, the binary file created).
To illustrate this attribute further, consider the output obtained (using the code above) from a executable created with a 64-bit non-LLP64 compiler (as shown by:

) in which the size of the short (in blue) has not changed; however, the size of the int (in red) has increased to 8 bytes (which is to be expected), while the amount of padding (in green) has also increased (because of alignment rules) to 6 bytes.
Conversely, attempting to load the 32-bit Chicken object (presented earlier in the discussion) into a 64-bit application that expects a 64-bit Chicken object (shown above) via:
Chicken Rooster;
ifstream in("output.bin", ios::binary);
in.read((char*) &Rooster, sizeof(Chicken));
in.close();is not going to produce the results that might be casually expected. Additionally, even if it is assumed that the size of the specified data type is consistent across multiple platforms, the issue of incompatible binary endianness can also wreak havoc if arbitrarily left to chance (this issue is predominantly encountered during cross-hardware development).
Likewise, although such concepts might be relatively straightforward to conceptually resolve, possibly through the utilization of individual structure read/write calls like:
in.read((char*) &Rooster.x, sizeof(short)); in.read((char*) &Rooster.y, sizeof(int));
or :
f.write((char*) &Hen.x, sizeof(short)); f.write((char*) &Hen.y, sizeof(int));
(albeit the individual reading and writing of structure elements would still produce incorrect results on a 64-bit non-LLP64 compiler, which is why class libraries with well defined data types are frequently utilized for cross-platform projects like GNU, or on systems with unmatched binary endianness); however, such solutions are oftentimes highly inconvenient (since simplistic changes to the data structure would also require changes to the read/write functions as well) and (while preserving CPU optimization via data alignment) are likely not the most desirable method (especially since what could have been haphazardly done with one line of code now suddenly turns into something that is a function of the data structure itself).
Nevertheless, assuming for the moment that data sizes and endianness) remain consistent across the desired platform, a more enigmatic attribute (or possible security problem depending upon the application) can occur as a inadvertent consequence of the compiler's tendency to align memory (particularly on simplistic compilers). Conversely, while the sequence of events that must occur in order for this particular phenomenon to run rampant in the wild is rather extensive (which makes this possibility rather remote); however, consider the following code:
#include <iostream>
#include <fstream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
using namespace std;
struct Chicken
{
short x;
// Emulate a 64 bit complier with no LLP64 support
__int64 y;
};
int main()
{
// emulate heap memory
void * stack = (char *)malloc(20);
// emulate a bad new or malloc command
char * password = (char *) stack;
// Pretend we have a password application
strcpy(password,"password");
// emulate a bad free or delete command
password = 0;
// emulate a bad new or malloc command
Chicken * Hen = (Chicken *)stack;
Hen->x =1;
Hen->y =9;
ofstream f2("output.bin", ios::binary);
f2.write((char*) Hen, sizeof(Chicken));
f2.close();
free(stack);
}
(in which the malloc/new and free/delete commands are emulated to demonstrate a simplistic compiler) and the corresponding output produced:

that contains sensitive information embedded within the padded memory structure (shown by the color green).
Likewise, examination of the output produced (as shown above) reveals that the dynamic allocation of aligned memory on the heap (particularly on a compiler that does not scrub memory upon executing the new or delete command, which is, fortunately, not the case within the Visual Studio's compiler) can result in the leakage of sensitive information that (in turn) could be easily and inadvertently saved or transmitted via structured memory input/output commands (like fstream read() or write()).
Nevertheless, while the list of problems associated with directly transferring an aligned structure (into or from a file, over a network, et cetera) are numerous (and a number of these problems were addressed above); however, solutions ( to such problems) can be equally problematic (predominantly for the reasons mentioned above) and ultimately must be weighed against the intended goal/scope of the application being created.
For example, the alignment attribute can be overridden (via the #pragma pack precompiler directive), like so:
#pragma pack(push)
#pragma pack(1)
struct Chicken
{
short x;
int y;
};
#pragma pack(pop)
, and the structure object can simply be read/written without the introduction of padding (via the commands previously discussed); however, the consequences of doing this inevitably includes the possibility of performance loss (or even program crashes on some finicky processors) and such techniques will not resolve the looming issue of consistent primitive type sizes (across different N-bit platforms) or hardware endianness issues. Yet, (despite such assessments) it should be recognized that (such assessments) might be (in truth) overtly harsh, especially given the success such techniques have had across PC platforms (noting that NetStorm: Islands At War did utilize this technique frequently, with some minor precautionary measures, within it's network code with great success).
Additionally, although structure packing may or may not be a good fit (depending upon the nature of the application), in more dynamic/diverse scenarios the utilization of individual (or custom tailored) element access (like so:
in.read((char*) &Rooster.x, sizeof(short)); in.read((char*) &Rooster.y, sizeof(int)); f.write((char*) &Hen.x, sizeof(short)); f.write((char*) &Hen.y, sizeof(int));
), while requiring more effort than simply reading/writing an object from memory, is often times the safer solution that is intrinsically somewhat unavoidable (especially given the inability, within C++, to reflect into a structure, like Java, for structural information); however, there are a number of tricks that can make structure allocation friendlier to dynamically transverse. For example, a constructor could be utilized (within the structure) to initialize the structure (like so:
struct Chicken
{
short x;
int y;
Chicken()
{
for(int lp=0;lp<sizeof(Chicken);lp++)
{
*(((char *)this)+lp) = 0xFF;
}
x=0;
y=0;
}
};, in which the padded structure values received the initial value 0xFF while the legitimate structure fields are initialized to 0), such that an algorithm (like so:
char * MakeAccessMap(void * input,int size)
{
char * output = new char[size];
for(int lp=0;lp<size;lp++)
{
if(*((unsigned char *)input+lp)==0xFF)
{
output[lp] = 0;
}
else
{
output[lp] = 1;
}
}
return output;
}
void WriteObject(ofstream * f,void * input, char * map,int size)
{
for(int lp=0;lp<size;lp++)
{
if(map[lp]==1)
{
f->write((((char *)input)+lp), 1);
}
else
{
continue;
}
}
}
void ReadObject(ifstream * f,void * output, char * map, int size)
{
for(int lp=0;lp<size;lp++)
{
if(map[lp]==1)
{
char x;
f->read((char*) &x, sizeof(char));
*(((char *)output)+lp) = x;
}
else
{
continue;
}
}
}
Chicken Hen;
char * HenMap = MakeAccessMap(&Hen,sizeof(Chicken));
Hen.x=7;
Hen.y=8;
ofstream f("output.bin", ios::binary);
WriteObject(&f,&Hen,HenMap,sizeof(Chicken));
f.close();
Chicken Rooster;
ifstream in("output.bin", ios::binary);
ReadObject(&in,&Rooster,HenMap,sizeof(Chicken));
in.close();
delete HenMap;) could be written to dynamically identify the location of padded segments and allow compression/expansion prior to performing read/write operations.
Likewise, structural techniques ( similar to creating a linked list) could also be employed here (in conjunction with overloading basic types to handle read/write functionality) in order to obtain similar (and likely more elegant looking) results, while other (more generic) solutions ( and extreme example being XML or JSON formatted input/output) could also be utilized as well for increased compatibility at the cost of having to add additional overhead (also a precompiler Perl or Python script, capable of generating generic c++ read/write calls, should also be considered here as well).
Nevertheless, although the possible solutions to such problems are rather vast (and i do recommend googling for projects that focus solely upon this particular peculiarity), ultimately the implementation of such solutions are rather moot if the necessity for such solutions remain unknown. Likewise, it is my hope that this article has helped enlighten (or at least clarified) this particular (and rather unique) C++ attribute and has aided you (though admittedly this is more of an introductory article than an in-depth explanation) in your cross-platform/cross-programming/cross-hardware/cross-memory-optimization endeavors.
At any rate, I hope you enjoyed reading this article!
By Mike Mclain